Perceptron (1958)
Frank Rosenblatt
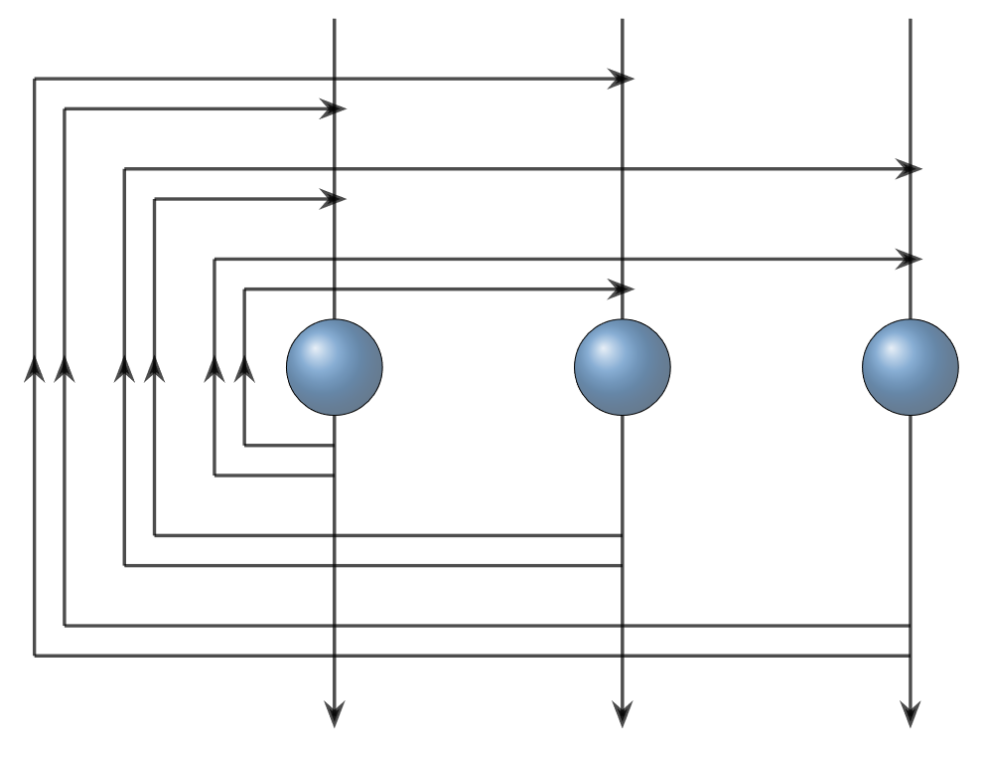
Neural network research begins with the first implementation of an artificial neuron called the perceptron. The theory for the perceptron was introduced in 1943 by McCulloch and Pitts as a binary threshold classifier. The first implementation was actually intended to be a machine rather than a program. Photocells were interconnected with potentiometers that were updated during learning with electric motors.
Neocognitron (1979)
Kunihiko Fukushima
A lesser known piece of history. The earliest inspiration for convolutional neural networks comes from Japan in the midst of the AI winter. A breakthrough development for computer vision, the neocognitron utilizes alternating layers of locally connected feature extraction and positional shift cells.
Hopfield Network (1982)
John Hopfield
The Hopfield network is a type of recurrent network based on bidirectional connections between neurons. Hopfield networks are a type of Ising model (also known as spin glass) that use Hebbian learning to train associative memory systems.
Boltzmann Machine (1985)
David Ackley, Geoffrey Hinton, Terrence Sejnowski
The Boltzmann Machine is a type of probabilistic graph model that consists of binary stochastic units and weights learned through an energy based minimization algorithm called contrastive divergence. The name comes from using the Boltzmann distribution to model the joint probability distribution of the input data.
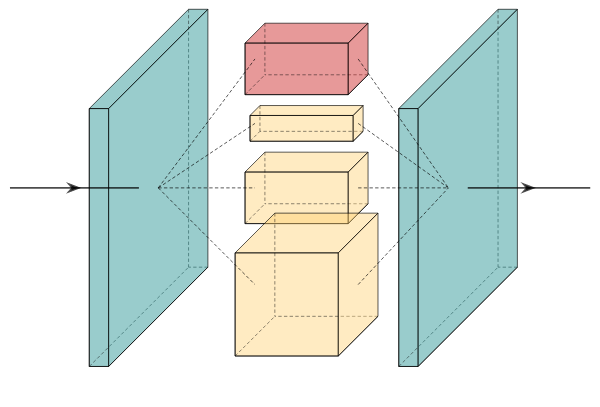
LeNet (1989)
Yann LeCun, Bernhard Boser, John Denker, Donnie Henderson, Richard Howard, Wayne Hubbard, Lawrence Jackel
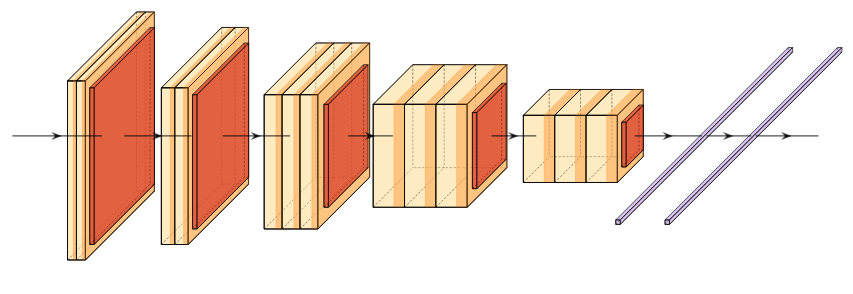
LeNet is the earliest introduction of the modern convolutional architecture. It contains three alternating convolutional and pooling layers followed by two fully connected layers. This model was introduced alongside the back propagation algorithm which produced incredible results at the time for image classification.
Long Short-Term Memory (1991)
Sepp Hochreiter, Jürgen Schmidhuber
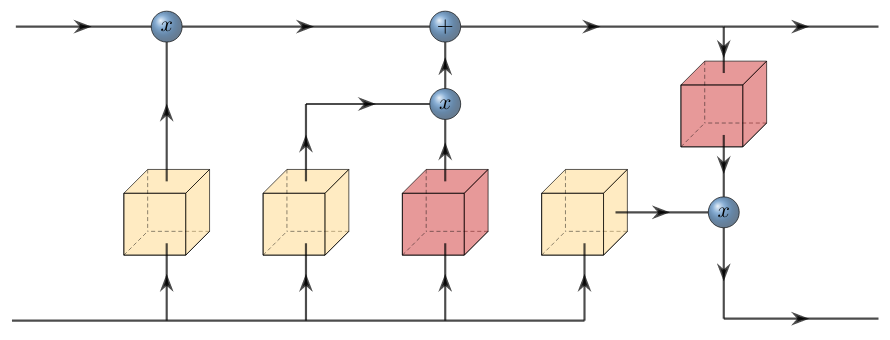
The LSTM is a recurrent network that contains a memory cell and three gating units (input, output, and forget) that regulate the flow of information into and out of the cell. The memory cell can selectively remember or forget information over long periods of time.
Echo State Network (2002)
Herbert Jaeger
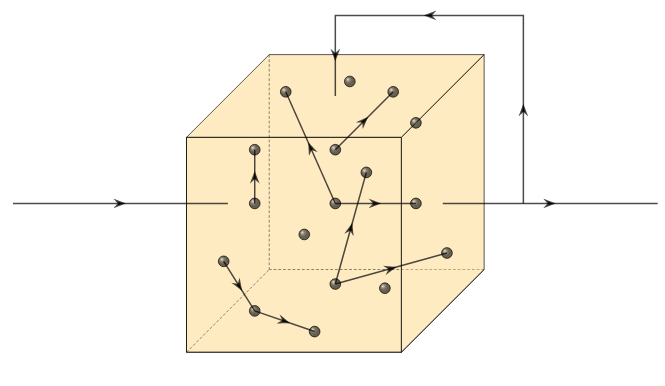
The echo state network is a type of recurrent architecture that utilizes a reservoir of fixed and randomly weighted connections that remain frozen during training. Only layers outside of the reservoir are optimized. The dynamic behavior of the reservoir generates complex temporal patterns which create an echo of the input signal.
Liquid State Machine (2004)
Wolfgang Maass, Henry Markram
The liquid state machine is closely related to the echo state network but utilizes a reservoir of randomly connected spiking neurons. The dynamic reservoir produces complex spatio-temporal activation patterns that are read out by linear discriminant units.
AlexNet (2012)
Alex Krishevsky, Ilya Sutskever, Geoffrey Hinton
The model that kickstarted the deep learning revolution. Consisting of eight layers, including five convolutional layers and three fully connected layers. AlexNet was one of the first deep convolutional neural networks to achieve state-of-the-art results on ImageNet. The original implementation split the network over two independent gpus to alleviate challenges with memory at the time.
VGG (2014)
Karen Simonyan, Andrew Zisserman
The Visual Geometry Group developed this network architecture that is characterized by its simplicity and uniformity. This model popularized the 3x3 convolutional filter size and its design has influenced the development of modern convolutional architectures.
Inception (2014)
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich
Inception is a deep convolutional network developed by Google researchers. It introduced the concept of inception modules, which are composed of multiple parallel convolutional layers of different kernel sizes to capture different feature scales.
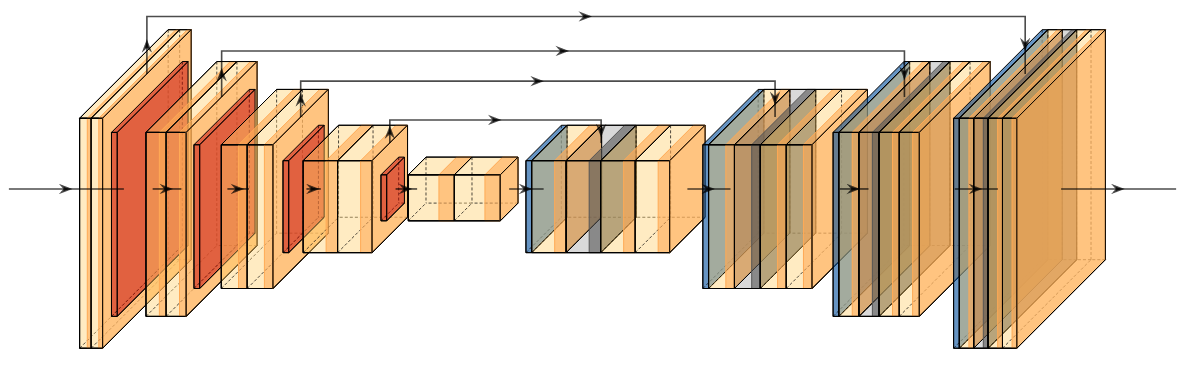
U-Net (2015)
Olaf Ronneberger, Philipp Fischer, Thomas Brox
U-Net is widely used in various segmentation and image-to-image translation tasks. The architecture consists of a contracting path that uses convolutional and pooling layers to capture context and a symmetric expanding path that uses deconvolutional and upsampling layers to achieve localization. The architecture's unique U-shape allows it to preserve fine-grained details during upsampling and is particularly well-suited for segmenting structures with varying shapes and sizes.
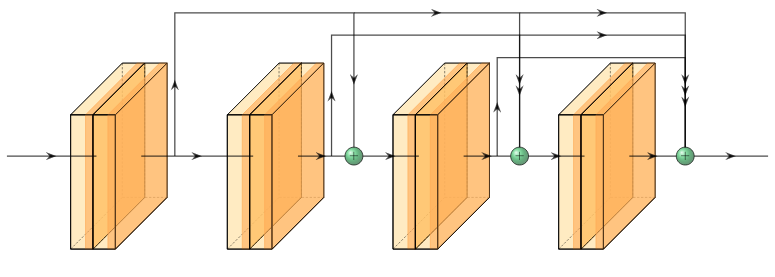
ResNet (2016)
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
Residual Networks popularized skip connections in deep networks to alleviate vanishing gradient problems. The shortcut connections between blocks allows the gradients to flow directly from later layers to earlier layers, enabling depths of over a hundred layers.
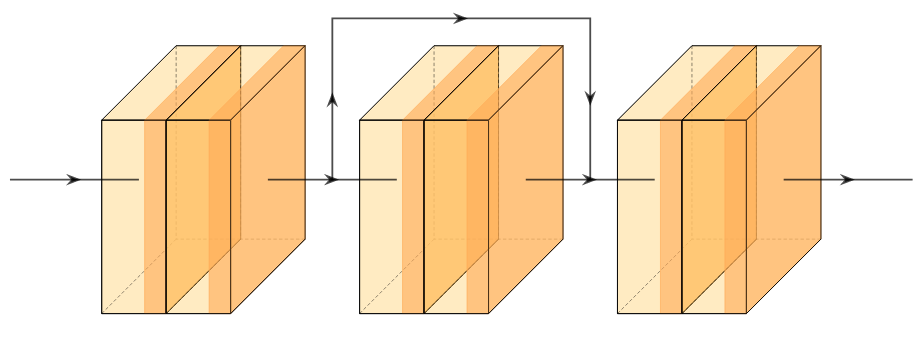
DenseNet (2016)
Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Weinberger
DenseNet builds on top of the ideas introduced in residual networks by implementing skip connections between a given layer and every other successive layer following it. Each layer receives a concatenation of all the feature maps of all the layers preceding it. This allows for learning at different levels of abstraction throughout the network.
SqueezeNet (2016)
Forrest Iandola, Song Han, Matthew Moskewicz, Khalid Ashraf, William Dally, Kurt Keutzer
SqueezeNet is notable for achieving comparable accuracy to larger neural network architectures while using significantly fewer parameters. SqueezeNet utilizes fire modules that consist of a 1x1 convolutional squeeze layer followed by a 3x3 convolutional expand layer.
ShuffleNet (2017)
Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun
ShuffleNet is a mobile optimized network that uses a combination of depthwise separable convolutions, channel shuffle operations, and pointwise convolutions to greatly reduce computational cost while maintaining accuracy.
Transformer (2017)
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Lion Jones, Aidan Gomez, Lukasz Kaiser, Illia Polosukhin
These models replace the traditional recurrent and convolutional networks with a self attention mechanism that allows the model to attend to different parts of the input sequence to generate contextual representations. The transformer consists of an encoder and decoder architecture that perform input/output mapping.
EfficientNet (2019)
Mingxing Tan, Quoc Le
EfficientNet uses a compound scaling method that optimizes the depth, width, and resolution of the network for a given amount of computational resources. EfficienNet utilizes a combination of residual inverted bottlenecks and squeeze-and-excitation blocks.
MLP Mixer (2021)
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy
A new take on vision architectures that eschew convolution and attention for only fully connected layers. MLP mixer applies spatial embeddings to the input image and then applies permutation-invariant operations through channel and token mixing layers.